|
|
| (5 intermediate revisions by 2 users not shown) |
| Line 1: |
Line 1: |
| − | [[Category:Functions]] | + | [[Category:How_To]] |
| | | | |
| | = Overview = | | = Overview = |
| Line 15: |
Line 15: |
| | <p> | | <p> |
| | | | |
| − | <p>Data Validation can either be performed via the web User Interface of the Fusion Registry, or by POSTing data directly to the Fusion Registries' data validation web service.</p> | + | <p>Data Validation can either be performed via the web User Interface of the Fusion Registry, or by POSTing data directly to the Fusion Registries' [[Data_Validation_Web_Service|data validation web service]].</p> |
| | | | |
| | = Syntax Validation = | | = Syntax Validation = |
| Line 99: |
Line 99: |
| | |} | | |} |
| | | | |
| − | = Web Service = | + | = Validation With Transformation = |
| | + | Fusion Registry supports a validation process, which combines both data validation with data transformation. The output can just be the valid dataset (with invalid observations removed) or both the valid dataset, and invalid dataset. |
| | | | |
| − | == Overview ==
| + | See the [[Data_Validation_Web_Service|Data Validation Web Service]] for details on how to achieve this. |
| − | {| class="wikitable"
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Entry Point</b>|| <b> /ws/public/data/validate </b>
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Access</b>|| <span style='color:green'><b>Public</b></span> (default). Configurable to Private
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Http Method</b>|| POST
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Accepts</b>|| CSV, XLSX, SDMX-ML, SDMX-EDI (any format for which there is a Data Reader)
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Compression</b> || Zip files supported, if loading from URL gzip responses supported
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Content-Type</b>|| <p>1. multipart/form-data (if attaching file) – the attached file must be in field name of uploadFile</p>
| |
| − | <p>2. application/text or application/xml (if submitting data in the body of the POST)</p>
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Response Format</b>|| application/json
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Response Statuses</b>|| <p><b>200</b> - Validation could be performed</p>
| |
| − | <p><b>400</b> - Validation could not be performed (either an unreadable dataset, or unresolvable reference to a required structure)</p>
| |
| − | <p><b>401</b> - Unauthorized (if access has been restricted)</p>
| |
| − | <p><b>500</b> - Server Error</p>
| |
| − | |}
| |
| − | | |
| − | == HTTP Headers==
| |
| − | {| class="wikitable"
| |
| − | |-
| |
| − | !|HTTP Header || Purpose || Allowed Values
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Data-Format</b>|| Used to inform the server when the data is in CSV format. ||csv;delimiter=[delimiter]
| |
| − | <p>Where [delimiter] is either:</p>
| |
| − | <ul>
| |
| − | <li>comma</li>
| |
| − | <li>tab</li>
| |
| − | <li>semicolon</li>
| |
| − | <li>space</li>
| |
| − | </ul>
| |
| − | |- | |
| − | |style="background-color:#eaecf0"|<b>Structure</b> || <p>(optional) Provides the structure to validate the data against.</p>
| |
| − | | |
| − | <p>This is optional as this information may be present in the header of the DataSet. If provided this value will override the value in the dataset (if present).</p>
| |
| − | || Valid SDMX URN for Provision Agreement, Dataflow, or Data Structure Definition
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Inc-Metrics</b><p style="font-size:0.85em">(Since v9.8)</p>||
| |
| − | <p>Optional. Includes metrics on the validation.</p>
| |
| − | <p>This will add extra detail to the validation report.</p>
| |
| − | ||Boolean (true/false)
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Inc-Valid</b><p style="font-size:0.85em">(Since v9.8)</p>||<p>Optional. Instructs the service to include a dataset with all the valid series and observations in the response.</p>
| |
| − | | |
| − | <p>As the result will contain a separate file for the dataset, the response format will be set to either multipart/mixed message with a boundary per file, or if the Zip header is set to true, the output will be a single zip file.</p>
| |
| − | <p>The file is called ValidData with the file extension based on the output format.</p>
| |
| − | ||Boolean (true/false)
| |
| − | | |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Inc-Invalid</b><p style="font-size:0.85em">(Since v9.8)</p>||<p>
| |
| − | Optional. Instructs the service to include a dataset with all the invalid series and observations in the response. </p>
| |
| − | | |
| − | <p>As the result will contain a separate file for the dataset, the response format will be set to either multipart/mixed message with a boundary per file, or if the Zip header is set to true, the output will be a single zip file.</p>
| |
| − | <p>The file is called InvalidData with the file extension based on the output format.</p>
| |
| − | | |
| − | ||Boolean (true/false)
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Accept</b><p style="font-size:0.85em">(Since v9.8)</p>||<p>Optional. Instructs the service which data output format to output the valid or invalid datasets in.
| |
| − | </p>
| |
| − | <p>This Header is only used if Inc-Valid or Inc-Invalid are set to true.</p>
| |
| − | ||See Accept formats for REST Data Query
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Zip</b><p style="font-size:0.85em">(Since v9.8)</p>||Optional. Compresses the output as a zip file. If used in conjunction with <b>Inc-Valid</b> or <b>Inc-Invalid</b> the zip will contain multiple files.
| |
| − | ||Boolean (true/false)
| |
| − | |-
| |
| − | |style="background-color:#eaecf0"|<b>Prior-Data-Dependent</b><p style="font-size:0.85em">(Since v9.8)</p>||<p>
| |
| − | Optional. This allows data to be validated under the assumption that other data will provide missing information. If this value is set to true, particular data validators will not be used when validating the data. These validators are "Mandatory Observations" and "Valid Calculations".</p>
| |
| − | | |
| − | <p>Default value is false.</p>
| |
| − | | |
| − | ||Boolean (true/false)
| |
| − | |}
| |
| − | | |
| − | == Response ==
| |
| − | <p>
| |
| − | The validation output contains both human readable error descriptions, as well as machine processible locations of the errors within the dataset. The location in the dataset is described as a key or observation locator in the format; A:UK:M:2008 – where each component relates to the Dimension value, separated by a colon. If the error position is observation, the last part of the key is the observation time period.</p>
| |
| − | | |
| − | <p>There are 3 types of output that can be produced which share a common structure: unable to parse input(returns HTTP 400); able to parse input but references invalid data structure (returns HTTP 200); parsed input and returns output, which may have validation errors (return HTTPS 200). Below are examples of each:</p>
| |
| − | | |
| − | === Valid Dataset ===
| |
| − | | |
| − | {
| |
| − | "Meta": {
| |
| − | "RequestTime": 1564410081711,
| |
| − | "Duration": 43
| |
| − | },
| |
| − | "FileFormat": "Structure Specific (Compact) v2.1",
| |
| − | "Prepared": "2019-07-29T10:23:01",
| |
| − | "SenderId": "FR_DEMO",
| |
| − | "DataSetId": null,
| |
| − | "Status": "Complete",
| |
| − | "Errors": false,
| |
| − | "Datasets": [
| |
| − | {
| |
| − | "DSD": "urn:sdmx:org.sdmx.infomodel.datastructure.DataStructure=OECD:HIGH_AGLINK_2011(1.0)",
| |
| − | "Dataflow": "urn:sdmx:org.sdmx.infomodel.datastructure.Dataflow=OECD:AGRIC_OUTLOOK_2011_2020(1.0)",
| |
| − | "DataProvider": "urn:sdmx:org.sdmx.infomodel.base.DataProvider=METATECH:DATA_PROVIDERS(1.0).METATECH",
| |
| − | "ProvisionAgreement": "urn:sdmx:org.sdmx.infomodel.registry.ProvisionAgreement=OECD:OECD_AGRIC_OUTLOOK(1.0)",
| |
| − | "KeysCount": 2,
| |
| − | "ObsCount": 62,
| |
| − | "GroupsCount": 0,
| |
| − | "Errors": false
| |
| − | "ReportedPeriods": {
| |
| − | "A": {
| |
| − | "Name": "Annual",
| |
| − | "StartPeriod": "1990",
| |
| − | "EndPeriod": "2020"
| |
| − | }
| |
| − | },
| |
| − | }
| |
| − | ],
| |
| − | "PreventsConversion": false,
| |
| − | "PreventsPublication": false
| |
| − | }
| |
| − | | |
| − | | |
| − | === Dataset with Errors ===
| |
| − | {
| |
| − | "Meta": {
| |
| − | "RequestTime": 1564401209760,
| |
| − | "Duration": 34
| |
| − | },
| |
| − | "InvalidData": {
| |
| − | "Datasets": [
| |
| − | {
| |
| − | "Structure": "urn:sdmx:org.sdmx.infomodel.registry.ProvisionAgreement=OECD:OECD_AGRIC_OUTLOOK(1.0)",
| |
| − | "Series": 2,
| |
| − | "Observations": 61,
| |
| − | "Groups": 0
| |
| − | }
| |
| − | ]
| |
| − | },
| |
| − | "ValidData": {
| |
| − | "Datasets": [
| |
| − | {
| |
| − | "Structure": "urn:sdmx:org.sdmx.infomodel.registry.ProvisionAgreement=OECD:OECD_AGRIC_OUTLOOK(1.0)",
| |
| − | "Series": 2,
| |
| − | "Observations": 32,
| |
| − | "Groups": 0
| |
| − | }
| |
| − | ]
| |
| − | },
| |
| − | "FileFormat": "Structure Specific (Compact) v2.1",
| |
| − | "Prepared": "2019-07-29T10:23:01",
| |
| − | "SenderId": "FR_DEMO",
| |
| − | "DataSetId": null,
| |
| − | "Status": "Complete",
| |
| − | "Errors": true,
| |
| − | "Datasets": [
| |
| − | {
| |
| − | "DSD": "urn:sdmx:org.sdmx.infomodel.datastructure.DataStructure=OECD:HIGH_AGLINK_2011(1.0)",
| |
| − | "Dataflow": "urn:sdmx:org.sdmx.infomodel.datastructure.Dataflow=OECD:AGRIC_OUTLOOK_2011_2020(1.0)",
| |
| − | "DataProvider": "urn:sdmx:org.sdmx.infomodel.base.DataProvider=METATECH:DATA_PROVIDERS(1.0).METATECH",
| |
| − | "ProvisionAgreement": "urn:sdmx:org.sdmx.infomodel.registry.ProvisionAgreement=OECD:OECD_AGRIC_OUTLOOK(1.0)",
| |
| − | "KeysCount": 3,
| |
| − | "ObsCount": 93,
| |
| − | "GroupsCount": 0,
| |
| − | "ReportedPeriods": {
| |
| − | "A": {
| |
| − | "Name": "Annual",
| |
| − | "StartPeriod": "1990",
| |
| − | "EndPeriod": "2020"
| |
| − | }
| |
| − | },
| |
| − | "Errors": true,
| |
| − | "ValidationReport": [
| |
| − | {
| |
| − | "Type": "Constraint",
| |
| − | "Errors": [
| |
| − | {
| |
| − | "Message": "Disallowed Dimension Value: REF_AREA=AFR",
| |
| − | "Dataset": 0,
| |
| − | "ComponentId": " REF_AREA ",
| |
| − | "ReportedValue": "AFR",
| |
| − | "Position": "Series",
| |
| − | "Keys": ["AFR:BT:AA"]
| |
| − | }
| |
| − | ]
| |
| − | },
| |
| − | {
| |
| − | "Type": "Representation",
| |
| − | "Errors": [
| |
| − | {
| |
| − | "Message": "Dimension 'VARIABLE' is reporting value 'AA' which is not a valid representation in referenced Codelist 'OECD:CL_HIGH_AGLINK_2011_VARIABLE(1.0)'",
| |
| − | "Dataset": 0,
| |
| − | "Position": "Series",
| |
| − | "ComponentId": "VARIABLE",
| |
| − | "ReportedValue": "AA",
| |
| − | "Keys": ["AFR:BT:AA"]
| |
| − | },
| |
| − | {
| |
| − | "Message": "Error in Primary Measure 'OBS_VALUE': Reported value 'XXX' is not of expected type 'Double'",
| |
| − | "Dataset": 0,
| |
| − | "ComponentId": " OBS_VALUE",
| |
| − | "ReportedValue": "XXX",
| |
| − | "Position": "Observation",
| |
| − | "Keys": ["AFR:BT:IM:2010"]
| |
| − | }
| |
| − | ]
| |
| − | },
| |
| − | {
| |
| − | "Type": "FormatSpecific",
| |
| − | "Errors": [
| |
| − | {
| |
| − | "Message": "Unexpected attribute 'ASD' for element 'StructureSpecificData/DataSet/Series/Obs'",
| |
| − | "Dataset": 0,
| |
| − | "Position": "Dataset"
| |
| − | }
| |
| − | ]
| |
| − | }
| |
| − | ]
| |
| − | }
| |
| − | ],
| |
| − | "PreventsConversion": false,
| |
| − | "PreventsPublication": true
| |
| − | }
| |
| − | | |
| − | <p>Note the first three elements ‘Meta’, ‘InvalidData’, ‘ValidData’, there are present in the report if Inc-Metrics is set to true. Inc-valid and Inc-Invalid set to true enables the report to know the metrics for the invalid and valid data.</p>
| |
| − | <p>Note also each Error has a Type, this is the category of error which caused the validator to fail. For a list of all validators see the following section on Validators.
| |
| − | The Error Position is either set to Dataset, Series, Observation, or Group. </p>
| |
| − | <p>PreventsConversion and PreventsPublication is an indication on the severity of the error. These settings on which errors prevent conversion and publication can be set in the Fusion Registry by the administrator of the system.</p>
| |
| − | | |
| − | === Dataset with an Unresolvable Datset Reference ===
| |
| − | {
| |
| − | "FileFormat": "Generic v2.1",
| |
| − | "MimeType": "application/xml",
| |
| − | "Status": "InvalidRef",
| |
| − | "Errors": true,
| |
| − | "Datasets": [{"Dataflow": "urn:sdmx:org.sdmx.infomodel.datastructure.Dataflow=BIS:INVALID_DATAFLOW(1.0)"}]
| |
| − | }
| |
| − | <p><b>Errors</b> has a value of true, the <b>Status</b> states InvalidRef, and the <b>Datasets</b> provides the reported reference which could not be resolved</p>
| |
| − | | |
| − | === Dataset which could not be read ===
| |
| − | {
| |
| − | "Status": "Error",
| |
| − | "Errors": true,
| |
| − | "Error": "Unexpected '<' character in element (missing closing '>'?)\r\n at [row,col {unknown-source}]: [17,3]"
| |
| − | }
| |
| − | <p>This error will be reported when the Fusion Registry is unable to determine what type of data the dataset is, so is unable to process the dataset for validation</p>
| |
| | | | |
| | = Performance = | | = Performance = |
| Line 392: |
Line 149: |
| | <p><b>Note 1:</b> All times are rounded to the nearest second</p> | | <p><b>Note 1:</b> All times are rounded to the nearest second</p> |
| | <p><b>Note 2:</b> Total duration includes other processes which are not included in this table</p> | | <p><b>Note 2:</b> Total duration includes other processes which are not included in this table</p> |
| | + | |
| | + | = Web Service = |
| | + | As an aternative to the Fusion Registry web User Interface [[Data_Validation_Web_Service|data validation web service]] can be used to validate data from external tools or processes. |
| | + | |
| | | | |
| | = Security = | | = Security = |
Overview
The Fusion Registry is able to validate datasets for which there is a Dataflow present in the Registry.
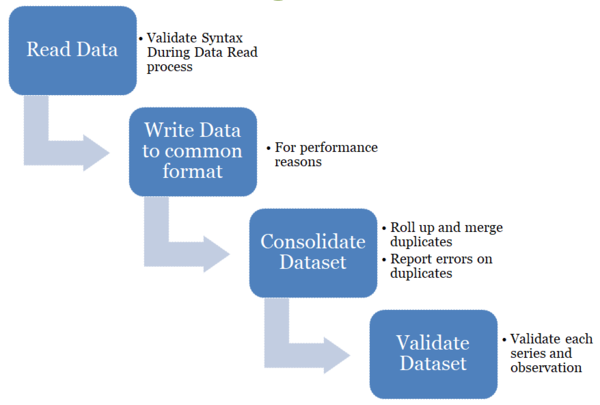
Data Validation is split into 3 high level validation process:
- Syntax Validation - is the syntax of the dataset correct
- Duplicates - format agnostic process of rolling up duplicate series and obs
- Syntax Agnostic Validation - does the dataset contain the correct content
Data Validation can either be performed via the web User Interface of the Fusion Registry, or by POSTing data directly to the Fusion Registries' data validation web service.
Syntax Validation
Syntax Validation refers to validaiton of the reported dataset in terms of the file syntax. If the dataset is in SDMX-ML then this will ensure the XML is formatted correctly, and the XML Elements and XML Attributes are as expected. If the dataset is in Excel Format (propriatory to the Fusion Registry) then these checks will ensure the data complies with the expected Excel format.
Duplicates Validation
Part of the validation process is the consolidation of a dataset. Consolidation refers to ensuring any duplicate series are 'rolled up' into a single series. This process is important for data formats such as SDMX-EDI, where the series and observation attributes are reported at the end of a dataset, after all the observation values have been reported.
Example: Input Dataset Unconsolidated
| Frequency |
Reference Area |
Indicator |
Time |
Observation Value |
Observation Note
|
| A |
UK |
IND_1 |
2009 |
12.2 |
-
|
| A |
UK |
IND_1 |
2010 |
13.2 |
-
|
| A |
UK |
IND_1 |
2009 |
- |
A Note
|
After Consolidation:
| Frequency |
Reference Area |
Indicator |
Time |
Observation Value |
Observation Note
|
| A |
UK |
IND_1 |
2009 |
12.2 |
A Note
|
| A |
UK |
IND_1 |
2010 |
13.2 |
-
|
The above consolidation process does not report the duplicate as an error, as the duplicate is not reporting contradictory information, it is supplying extra information. If the dataset were to contain two series with contradictory observation values, or attributes, then this would be reported as a duplication error
Example: Duplicate error for the observation value reported for 2009
| Frequency |
Reference Area |
Indicator |
Time |
Observation Value |
Observation Note
|
| A |
UK |
IND_1 |
2009 |
12.2 |
-
|
| A |
UK |
IND_1 |
2010 |
13.2 |
-
|
| A |
UK |
IND_1 |
2009 |
12.3 |
A Note
|
Syntax Agnostic Validation
Syntax Agnostic Validation is where the majority of the data validation process happens. Like the name suggests, the validation is syntax agnostic, and therefore the same validation rules and processes are applied to all datasets, regardless of the format the data was uploaded in.
This validation process makes use of a single Validation Manager and multiple Validation Engines. The validation manager walks the contents of the dataset (Series and Observations) in a streaming fasion, and as each new Series or Observation is read in, it asks the same question to each registered Validation Engine - the question is "is this valid?".
An conceptual example of the Validation Manager delegating validation questions to each Validation Engine in turn
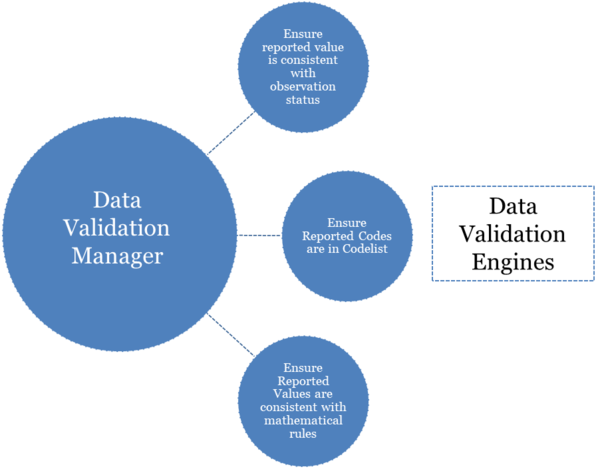
The purpose of a Validation Engine is to perform ONE type of validation, this allows configuration of each validation engine as a seperate entity, and new validation engines can be easily added to the product if there is a new type of validation rule to implement. Validation Engines can be switched off, or have a different level of error reporting set, validation engines can also have a error limit set, so that a single engine can be decommisioned from validating a particular dataset if it is reporting too many errors. In the validation report that is produced, the errors are grouped per validation engine.
The following table shows each validation engine and its purpose
| Validation Type |
Validation Description
|
| Structure |
Ensures the Dataset reports all Dimensions and does not include any additional Dimensions or Attributes
|
| Representation |
Ensures the reported values for Dimensions, Attributes, and Observation values comply with the DSD
|
| Mandatory Attributes
|
Ensures all Attributes, as defined in the Data Structure Definition (DSD), are reported if they are marked as Mandatory
|
| Constraints |
Ensures the reported values have not been disallowed due to Content Constraint definitions
|
| Mathematical Rules
|
Performs any mathematical calculations, defined in Validation Schemes, to ensure compliance
|
| Frequency Match
|
Ensure the reported Frequency code matches the reported time period
Example: FREQ=A will expect time periods in format YYYY
|
| Obs Status Match
|
Ensure observation values are in keeping with the Observation Status
Example: Missing Value, does not expect a value to be reported
|
| Missing Time Period
|
Ensures the Series has no holes in the reported time periods
|
Validation With Transformation
Fusion Registry supports a validation process, which combines both data validation with data transformation. The output can just be the valid dataset (with invalid observations removed) or both the valid dataset, and invalid dataset.
See the Data Validation Web Service for details on how to achieve this.
Performance
The data format has some impact on performance time, as the time taken to perform the initial data read and syntax specific validation rules are format specific. After the initial checks are performed, an intermediary data format is used to perform consolidation and syntax agnositc checks. Therefore the performance of the data consolidation stage and syntax agnostic data validaiton is the same regardless of import format.
Considerations to take to optimise performance is
- To reduce network traffic, upload the data file as a Zip
- In the case the dataset is coming from a URL support gzip response
-
- Use a fast hard drive to optimise I/O as temporary files will be used in the case of validating large datasets
- Performance is dependant on CPU speed
When the server recieves a zip file, there is some overhead in unzipping the file, but this overhead is very small compare to the performance gains in network transfer times.
Tests have been carried out on a dataset with the following properties
| Series |
216,338
|
| Observations |
15,470,893
|
| Dimensions |
15
|
| Datset Attributes |
3
|
| Observation Attributes |
2
|
The following table shows the file size, and validation duration for each data format
| Data Format |
File Size
Uncompressed |
File Size
Zipped |
Syntax Validation
(seconds) |
Data Consolidation
(seconds) |
Validate Dataset
(seconds) |
Total Duration
(seconds)
|
| SDMX Generic 2.1 |
3.6Gb |
94Mb |
165 |
37 |
57 |
312
|
| SDMX Compact 2.1 |
1.1Gb |
59Mb |
84 |
37 |
57 |
251
|
| SDMX JSON |
362Mb |
41Mb |
65 |
36 |
58 |
224
|
| SDMX CSV |
1.3Gb |
80Mb |
71 |
36 |
58 |
240
|
| SDMX EDI |
153Mb |
71Mb |
68 |
36 |
58 |
230
|
Note 1: All times are rounded to the nearest second
Note 2: Total duration includes other processes which are not included in this table
Web Service
As an aternative to the Fusion Registry web User Interface data validation web service can be used to validate data from external tools or processes.
Security
Data Validation is by default a public service and as such a user can perform data validation with no authentication required. It is possible to change the security level in the Registry to either:
- Require that a user is authenticated before they can perform ANY data validation
- Require that a user is authenticated before they can perform data validation on a dataset obtained from a URL

