Difference between revisions of "Fusion Data Mapper"
(→Registering a Series – Fusion Data Mapper) |
(→Add a Mapped Dataset – Fusion Data Mapper) |
||
| Line 141: | Line 141: | ||
#:::* the DSD must include a SERIES_CODE dimension | #:::* the DSD must include a SERIES_CODE dimension | ||
#:::* the SERIES_CODE dimension must be coded (conventionally, the Codelist is named CL_SERIES_CODE) | #:::* the SERIES_CODE dimension must be coded (conventionally, the Codelist is named CL_SERIES_CODE) | ||
| − | #:::* the codes of series in the Time Series Database to be included in the dataset must be ‘registered’ by adding them to the SERIES_CODE Codelist (refer to [[Registering a Series – Fusion Data Mapper | + | #:::* the codes of series in the Time Series Database to be included in the dataset must be ‘registered’ by adding them to the SERIES_CODE Codelist (refer to [[Registering a Series – Fusion Data Mapper:Registering a Series]]) |
#:::If an invalid DSD is chosen, the dataset will be created but it will be impossible to add series to it. | #:::If an invalid DSD is chosen, the dataset will be created but it will be impossible to add series to it. | ||
# Set the name for the new Dataset in the chosen language. This the descriptive name of mapped dataset’s Dataflow, for instance ‘Employment’, ‘National Accounts’ or ‘Financial Activity’. After the Dataset has been created, changes to the name, including adding alternative names in different languages, can be made using the Fusion Registry Administration Interface – Dataflow maintenance. In the example shown in Figure 1, the name has been set in Hebrew. | # Set the name for the new Dataset in the chosen language. This the descriptive name of mapped dataset’s Dataflow, for instance ‘Employment’, ‘National Accounts’ or ‘Financial Activity’. After the Dataset has been created, changes to the name, including adding alternative names in different languages, can be made using the Fusion Registry Administration Interface – Dataflow maintenance. In the example shown in Figure 1, the name has been set in Hebrew. | ||
Revision as of 04:22, 16 October 2019
Contents
- 1 Overview – Fusion Data Mapper
- 2 The Fusion Data Mapper User Interface
- 3 The Fusion Registry Administration Interface
- 4 Operating Procedures – Fusion Data Mapper
- 4.1 Add a Mapped Dataset – Fusion Data Mapper
- 4.2 Clone a Dataset – Fusion Data Mapper
- 4.3 Remove a Mapped Dataset – Fusion Data Mapper
- 4.4 Add Series to a Dataset – Fusion Data Mapper
- 4.5 Registering a Series – Fusion Data Mapper
- 4.6 Removing Series from a Dataset – Fusion Data Mapper
- 4.7 Maintaining Metadata Values on Series Interactively using the Web Interface – Fusion Data Mapper
- 4.8 Bulk Maintenance of Metadata Values using Excel Import / Export – Fusion Data Mapper
- 4.9 Default Code Values – Fusion Data Mapper
- 4.10 Codelists - Adding and Removing Codes – Fusion Data Mapper
- 4.11 Changing the Dimensionality of a Dataset – Fusion Data Mapper
- 5 Controlling User Privileges to Maintain and Browse Metadata Mappings
Overview – Fusion Data Mapper
This document provides guidance and operating procedures for creating and managing mapped datasets using Fusion Registry 9 and the Fusion Data Mapper.
Use Case
The primary use case is transforming single dimensional datasets to SDMX multi-dimensional structures.
Single dimensional datasets are those with a single unique identifier for each series (e.g. Series Code) such as created by FAME or similar time-series production systems.
One-to-one transformations only are supported by this version of the Fusion Data Mapper.
The transformation is performed by Fusion Registry using SDMX Structure Mapping. Fusion Data Mapper provides an easy-to-use user interface for defining and management the mapping rules.
Audience
- Metadata Managers – those responsible for managing the metadata mappings on the Bank’s catalogue of time series on a day to day basis.
- Metadata Superusers – those responsible for managing the core structural metadata including Agencies, Concepts, Data Structure Definitions and Codelists.
- System Administrators – those responsible for administering Fusion Registry 9 as part of the integrated statistical data and metadata system, and managing the Time Series Database as the source of observation data.
Prerequisites
Readers are assumed to have an understanding of basic SDMX principles and the purpose of the main SDMX structural metadata artefacts including Concepts, Codes and Codelists, Categories, Data Structure Definitions (DSDs), Dataflows, Provision Agreements, Structure Sets and Dataflow Maps.
Terminology
| Dataset | Dataset refers to a named collection of series that typically all fall under a specific topic, for instance ‘National Accounts’. In Fusion Registry, an SDMX Dataflow represents a dataset.
|
| Mapped Dataset | A Mapped Dataset is an SDMX Dataflow where data is taken from a ‘source’ Dataflow and transformed to different dimensionality using defined mapping rules. The Fusion Data Mapper manages these mapping rules.
In this document, the source Dataflow is assumed to be observation data from the Time Series Database which is described by a Data Structure Definition having only SERIES_CODE, TIME_PERIOD and OBS_VALUE dimensions.
|
| Time Series Database | The source of time series observation data without metadata that Fusion Registry maps to Mapped Datasets using the defined mapping rules. |
The Fusion Data Mapper User Interface

The Fusion Data Mapper is a web user interface providing the following main functions:
Authenticated users with sufficient structural metadata maintenance privileges
- Add and remove mapped datasets
- Add and remove series on mapped datasets
- Interactively set and change the metadata values on a series by series basis
- Export metadata values for selected series to Excel
- Import metadata values for defined series from Excel
- Change code names with impact analysis
Anonymous or authenticated users with sufficient privileges to view but not change the structural metadata
- Browse the catalogue of mapped datasets
- Examine the ‘definition’ of a dataset – its dimensionality and list of possible codes for each
- Dimension or Attribute
- Browse the series in each dataset
The Fusion Registry Administration Interface

The Administration Interface is Fusion Registry’s main web user interface.
For the purposes of managing the metadata on mapped datasets, it provides the following functions:
Authenticated users with sufficient structural metadata management privileges
- Create and modify SDMX Data Structure Definitions (DSDs)
- Create and modify SDMX Concepts
- Create and modify SDMX Codelists
- Add and remove codes from SDMX Codelists
- Register a series (series must be ‘registered’ before they can be mapped in dataset by adding the Series Code and Series Name to the relevant SERIES_CODE Codelist)
Refer to the Fusion Registry Structural Metadata Management Guide for general information on using the Fusion Registry Administration Interface for creating and maintaining core SDMX structure metadata artefacts including DSDs, Dataflows, Concepts, Categories and Codelists.
Operating Procedures – Fusion Data Mapper
Add a Mapped Dataset – Fusion Data Mapper
A mapped dataset is an SDMX Dataflow and an associated SDMX Dataflow Map that describes:
- (a) The dataset’s dimensionality using an SDMX Data Structure Definition (DSD)
- (b) The list of series in the dataset
- (c) The metadata values for each series
Use cases:
- Creating a new dataset
- Creating an alternative version of an existing dataset perhaps with a different compliment of series and / or dimensionality
- Creating an alternative version of a dataset with simplified dimensionality for public dissemination
The Fusion Data Mapper provides a convenient way to interactively manage the process. However, it is important to note that creating, modifying and examining the underlying SDMX artefacts can also be done using the Fusion Registry Administration Interface or the REST API which may be useful for debugging purposes. Discussion of these topics is outside of the scope of this document.
Add a Mapped Dataset - Prerequisites
- The DSD that you plan to use for the dataset must already exist. DSDs and their associated structures can be created and managed using the Fusion Registry Administration User Interface.
- The Source Dataset that contains the unmapped time series observations. The Source Dataset is an SDMX Dataflow created by a System Administrator that provides access to the Time Series Database observation data.
Add a Mapped Dataset - Required Roles and Privileges
To add a mapped dataset, the user must be a member of the Agency that owns the SDMX Structure Set, or a member of a parent Agency if a hierarchical agency structure is in place.
Once created, the SDMX Dataflow Map which represents the dataset will be owned by the same Agency as the SDMX Structure Set to which it belongs. Any subsequent changes to the dataset can only be performed by users who are a member of that Agency. Changes include:
- Removing the dataset
- Adding and removing series
- Maintaining the metadata values on series
Add a Mapped Dataset - Procedure
Using the Fusion Data Mapper:
- Choose the Add Dataset function from the left-hand menu bar.
- Choose a Source Dataset from those available. All Dataflows in the Fusion Registry with a single dimension are shown in this list. However, it is important that the single dimension of the chosen source dataset must be the Series Code. If multiple Source Datasets are shown in the list, care should be taken to choose the correct one otherwise it will be impossible to create the metadata mappings.
- Choose the Dataset Definition for the new dataset. A list of available Data Structure Definitions (DSDs) are shown to choose from.
- The DSD chosen for the new dataset must follow these rules:
- the DSD must include a SERIES_CODE dimension
- the SERIES_CODE dimension must be coded (conventionally, the Codelist is named CL_SERIES_CODE)
- the codes of series in the Time Series Database to be included in the dataset must be ‘registered’ by adding them to the SERIES_CODE Codelist (refer to Registering a Series – Fusion Data Mapper:Registering a Series)
- If an invalid DSD is chosen, the dataset will be created but it will be impossible to add series to it.
- The DSD chosen for the new dataset must follow these rules:
- Set the name for the new Dataset in the chosen language. This the descriptive name of mapped dataset’s Dataflow, for instance ‘Employment’, ‘National Accounts’ or ‘Financial Activity’. After the Dataset has been created, changes to the name, including adding alternative names in different languages, can be made using the Fusion Registry Administration Interface – Dataflow maintenance. In the example shown in Figure 1, the name has been set in Hebrew.
- Set the SDMX ID for the new dataset. The ID is the unique reference for the dataset’s SDMX Dataflow. You must follow these rules when choosing the ID:
- The ID must be unique
- The ID must use Latin characters and can contain letters, numbers and ‘_’ characters.
- It cannot contain dots (‘.’) or other special characters such as ‘@’ or ‘$’.
- The following are valid:
- EMPLOYMENT
- FINANCIAL_ACTIVITY2
- NATIONAL_ACCOUNTS
- By convention, IDs are in upper case. For example, use ‘NATIONAL_ACCOUNTS’ rather than ‘National_Accounts’
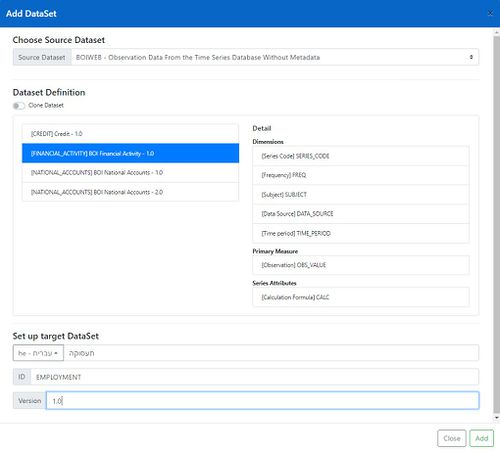
- Set the Version for the dataset. This will be used to set the version of the dataset’s SDMX Dataflow. Version numbers are of the form <major_number>.<minor_number>. The following are valid:
- 1.0
- 1.1
- 2.1
- By convention, the first version is 1.0.
- Create new versions of a dataset when you need to change the dimensionality – refer to Section 4.12 Changing the Dimensionality of a Dataset.
- Choosing ‘Add’ will create the new dataset which should then appear in the left-hand bar



Clone a Dataset – Fusion Data Mapper
Clone a dataset to create a copy of an existing dataset.
Use cases:
- Creating a copy of a dataset with the same dimensionality for experimentation or other purposes
- Creating a copy of a dataset with completely different dimensionality
- Adding or removing selected dimensions from a dataset
All of the series in the existing dataset are copied to the clone.
Where a dimension or attribute appears in both the original and clone datasets, the metadata values are copied. However, default values are used where a new dimension or mandatory attribute appears only in the clone dataset. Default Code Values explains how to define and manage default values.
Clone Dataset - Prerequisites
- The DSD that you plan to use for the dataset must already exist. DSDs and their associated structures can be created and managed using the Fusion Registry Administration User Interface.
- The Source Dataset that contains the unmapped time series observations. The Source Dataset is an SDMX Dataflow created by a System Administrator that provides access to the Time Series Database observation data.
Clone Dataset - Required Roles and Privileges
To add a mapped dataset, the user must be a member of the Agency that owns the SDMX Structure Set, or a member of a parent Agency if a hierarchical agency structure is in place.
Once created, the SDMX Dataflow Map which represents the dataset will be owned by the same Agency as the SDMX Structure Set to which it belongs. Any subsequent changes to the dataset can only be performed by users who are a member of that Agency. Changes include:
- Removing the dataset
- Adding and removing series
- Maintaining the metadata values on series
Clone Dataset – Procedure
The procedure for cloning a dataset is the same as that explained in Section 4.1 on how to add a mapped dataset, with the following exceptions:

- Choose the Clone Dataset option
- Choose a dataset to clone from – a list of existing datasets in the Structure Set is shown.
- Choose the Data Structure (DSD) for the new cloned dataset.
In the example shown in Figure 2, a clone is being made of the NATIONAL_ACCOUNTS dataset. A new DSD has been created called NATIONAL_ACCOUNTS Version 2.0 which adds new dimensions.
Use Case – Add a dimension to a dataset using the Clone Method
- Using the Fusion Registry Administration Interface, create a new DSD based on the original but including the new dimension. Either save the DSD with a new ID, or use the same ID with a different version number. For instance:
- Original: NATIONAL_ACCOUNTS version 1.0
- New: NATIONAL_ACCOUNTS version 2.0
- or: NEW_NATIONAL_ACCOUNTS version 1.0
- Using the Fusion Data Mapper, add a new dataset choosing the Clone Dataset option. Choose the existing dataset as the one to clone, and the newly created DSD. The procedure for this is explained below.
- The new dataset will be created by copying all of the series and their metadata values to the cloned dataset. The new dimension will have the default value for every series.
- Change the values for the new dimension as required. Section 4.7 explains how to do this interactively using the web user interface. Alternatively, export the mappings to Excel, make the necessary changes and import the results – this is explained in 'Bulk Maintenance of Metadata Values using Excel Import / Export'
- Save the mapping for the new dataset.
Remove a Mapped Dataset – Fusion Data Mapper
Mapped datasets created using the procedure describes in section 4.1 can be removed if required.
Removing a mapped dataset:
- Deletes the dataset’s SDMX Dataflow map; and
- Deletes the dataset’s SDMX Dataflow and associated Provision Agreements.
Use cases:
- Removing a redundant dataset – one which is no longer required
- Removing a dataset that has been created in error
The Source Dataset, the observation data, the DSD and the Codelists are not affected.
- Take care that, if required, the mapping rules (the list of series and the metadata values for each) are saved using the Excel Export function before removing a dataset.
Under certain conditions, datasets removed in error can be restored using the Fusion Registry metadata rollback function. This can only be done by a System Administrator and guidance should be sought from Metadata Technology Technical Support.
Remove a Mapped Dataset – Prerequisites
- The mapped dataset has been created using the procedure in Section 4.1.
Remove a Mapped Dataset - Required Roles and Privileges
To remove a mapped dataset, the user must be a member of the Agency that owns the SDMX Structure Set and Dataflow Map for the dataset, or a member of a parent Agency if a hierarchical agency structure is in place.
Remove a Mapped Dataset – Procedure
Using the Fusion Data Mapper:
- Choose the Dataset
- Choose the Delete Dataset option top button bar.
- A message box will be displayed asking for confirmation of the deletion. Choose ‘Ok’ to delete, or ‘Cancel’ to abort.
- Confirm that the dataset has been removed from the left-hand bar.

Add Series to a Dataset – Fusion Data Mapper
The process of adding a series to a dataset results in a mapping rule being added to the dataset’s SDMX Dataflow Map.
The mapping rule is described using an SDMX Value Map which, for each series in the mapped dataset, translates the Series Code of a series in the Time Series Database to a specified value for each of the dimensions in the dataset’s SDMX DSD.
For instance, a Value Map for the DEP_Q_N ‘Depreciation’ series may conceptually look like the following:
| Source dataset from Time Series Database | Mapped dataset | ||||
| Dimension | Code | Dimension | Code | Code Name | |
|---|---|---|---|---|---|
| SERIES_CODE | "DEP_Q_N" | ||||
| Maps to > | |||||
| SERIES_CODE | DEP_Q_N | "Depreciation" | |||
| DATA_TYPE | BAL | "Balance" | |||
| SERIES_TYPE | O | "Original” | |||
| FREQ | Q | "Quarterly" | |||
| UNITS | USD | "US Dollars | |||
| PRICE_BASE | FIX | “Fixed Prices” | |||
| ECONOMIC_AREA | FA | “Financial Activity” | |||
| SUBJECT | NA | “National Accounts” | |||
| DATA_SOURCE | CB | “Central Bank” | |||
| CALCULATION | “GDP.Q_N - GDP_PF_TAB_NET.Q_N - DEP.Q_N - TAX_NET_PROD.Q_N – M_TAX_NET.Q_N” | ||||
The process of creating and maintaining the SDMX Value Map is managed by the Fusion Data Mapper. If necessary, the SDMX Dataflow Map and its constituent Value Maps can be examined and manipulated using the Fusion Registry Administration Interface, or the REST API. These procedures are outside of the scope of this document.
Add Series – Prerequisites
- The mapped dataset has been created using the procedure described in Section 4.1.
- The series must have been registered with Fusion Registry. This means that the series code for the series to be added to the dataset must appear in the Codelist for the SERIES_CODE dimension in the DSD of the Mapped Dataset. The process for registering a series is described in 'Registering a Series.
- Note that series can be registered and added to a dataset without the observation data existing in the Time Series Database. End users querying for the series will see no results until the observation data is added.
Add Series – Required Roles and Privileges
To add series to a dataset, users must be a member of the Agency that owns the SDMX Structure Set and Dataflow Map that represents the dataset, or a member of a parent Agency if a hierarchical agency structure is in place.
Add Series – Procedure
There are two different methods for adding series to a dataset:
- Interactively using the web user interface
- Excel
Interactive Method
- Choose the Dataset.
- Choose the Add Series button.
- The Add Series window is displayed


The window displays a list of series known to Fusion Registry. Those with check-boxes can be selected and added to the dataset in one operation to the dataset using the Add button. The default value will be used for each dimension.
Series highlighted in red are in the Time Series Database (Source Dataset) but cannot be mapped into this dataset because they have not been ‘registered’. See Add a Mapped Dataset for guidance on registering series.
Series highlighted in green are already mapped into the current dataset.
The Filter Codes allows multilingual free-text search of the series codes and series names as plain text or by providing a regular expression. Any valid regex search pattern can be used and does not need to begin with a ^ or / control character. Example: MKR.*DEF[ABC]+
Three different views are available:
| All | All registered and un-registered series including those that have already been mapped into this dataset.
The All view can be used to identify whether a series is known to the system, and what its status is. Series listed in this view cannot be mapped if they are unregistered or have already been mapped into this dataset. |
| Not mapped in any dataset | Registered and un-registered series that have not been mapped into any dataset.
This is the default view. |
| Not mapped in this dataset | Registered and un-registered series that have not been mapped in this dataset. Series can be mapped into multiple datasets, so series that have already been mapped in other datasets will appear in this view. |
Excel Method
Series can be added in bulk to a Mapped Dataset by importing from an Excel spreadsheet. Note that the spreadsheet must follow a specific layout, as illustrated in Figure 4.

The following rules must be followed when building Excel workbooks for importing series mappings:
- The workbook must contain a single worksheet. The name of the worksheet is not significant.
- The first row (Row A) must contain a header with the IDs of the Dimensions and Attributes exactly as defined by the dataset’s DSD.
- The second and subsequent rows must contain the series to add to the dataset – one series per row. There can be no blank rows.
- Each series in the sheet must have a valid series code in the SERIES_CODE dimension. To be valid, the series must have been registered (see Section 4.5 for guidance on registering a series). However, the observation data for a series does not need to be in the Time Series
- Database.
Blank Cells and Default Value Behaviour
The default value will be used for coded dimensions where the cell is left blank (see Section 4.9 for more information on default values). In the example shown in Figure 4, leaving the UNITS cell blank for a series would result in the default ‘NIS’ value.
For un-coded attributes (CALCULATION_FORMULA in the example), no default will be used an empty cell will result in a blank value in mapped series output.
The default value behaviour allows a list of series to be added to the dataset, just by specifying the series codes in the spreadsheet. Once added, the metadata values can be set interactively for each series using the web interface. Figure 5 illustrates an Excel spreadsheet to add 10 series, all with default values.

Registering a Series – Fusion Data Mapper
Registering a Series – Fusion Data Mapper
Series must be ‘registered’ before they can be added to datasets.
A series is registered by adding the its series code to the SERIES_CODE Codelist or equivalent – the Codelist used for the SERIES_CODE dimension in the dataset’s DSD.
Note that this guide assumes a single Codelist named CL_SERIES_CODE is used for the entire system. In practice, separate series code Codelists could be used for each dataset which would allow different user groups to maintain their own series codes without having the rights to alter the codes owned by other groups.
in SDMX, each code in a Codelist has an ID and a Name – a multi-lingual description of the code. When registering a series, the Name should be set to the descriptive name of the series, for instance:
ID DEP_Q_N
Name (en) Depreciation Quarterly
Registering a Series – Prerequisites
- The CL_SERIES_CODE Codelist or equivalent must exist.
- A series code must be defined for the series that conforms to SDMX rules for structure IDs. In summary: the ID must use Latin characters and can contain letters, numbers and ‘_’ characters. It cannot contain dots (‘.’) or other special characters such as ‘@’ or ‘$’.
Registering a Series – Required Roles and Privileges
The user registering the series must be a member of the Agency that owns the Codelist, or a member of a parent Agency if a hierarchical agency structure is in place.
Registering a Series – Procedure
Using the Fusion Registry Administration Interface:
- Log in as a user with sufficient rights to maintain the relevant series code Codelist.
- Select the Codelist from the Items / Codelists menu. In the example shown below, the CL_SERIES_CODE is the single series Codelist used for the entire system
- Using the ‘Cogs’ menu, choose ‘Edit selected Codelist’.
- Proceed to Step 2 of the Codelist Wizard. Choose the language for the Series Name from the Language selector. Hebrew (he) has been chosen in the example shown. Multiple series can be added at once. Copy and paste, or manually enter a list of the new series to register into the ‘CSV’ form. Each row should follow the pattern:
- <Series Code ID> , <Series Name In Chosen Language>
- <Series Code ID> , <Series Name In Chosen Language>
- Choose ‘Finish’ to complete the process. View the Codelist to confirm that the new series have been added to the Codelist as expected. If so, the ‘registration’ process is complete for those series.
- Each series can have names in multiple alternative languages. To add the name to a series in an alternative language, repeat Steps 3 to 5. On Step 4, use the same series codes, but choose the appropriate language from the Language selector, and enter the Series Name in that language.



Removing Series from a Dataset – Fusion Data Mapper
Series can be removed from a dataset interactively using the web interface, or in bulk by using the Excel Import ‘Full Replace’ function. The process of removing a series from a mapped dataset removes the mapping rule only. The observation data is not affected, nor are rules for the same series that have been added to other datasets.
Removing Series – Prerequisites
- The dataset contains series that need to be removed.
Remove Series – Required Roles and Privileges
To remove series from a dataset, users must be a member of the Agency that owns the SDMX Structure Set and Dataflow Map that represents the dataset, or a member of a parent Agency if a hierarchical agency structure is in place.
Removing Series – Procedure
Interactive Method – To Remove Series Individually
Using the Metadata Management web interface:
- Choose the dataset and the ‘Manage Metadata’ option from the left-hand menu bar.
- Use the check boxes to select the series to delete.
- Confirm the deletion.
- Save the change using



Excel Method – To Remove Multiple Series in One Operation
The Excel Import “Full Replace” function can be used to quickly remove series in bulk from a dataset. The process involves exporting the mappings, removing the redundant series from the Excel spreadsheet, and re-importing the result specifying “Full Replace”. Refer to Section 4.8 for full details on the Excel Import / Export function.
Maintaining Metadata Values on Series Interactively using the Web Interface – Fusion Data Mapper
Use the Fusion Data Mapper to interactively set or change the metadata values for mapped series.
Maintaining Metadata Values on Series – Prerequisites
- One or more mapped datasets have been added (see Section 4.1).
- For each dataset, one or more series have been added (see Section 4.4).
Maintaining Metadata Values on Series – Required Roles and Privileges
To maintain metadata values on a series, users must be a member of the Agency that owns the SDMX Structure Set and the Dataflow Map that represents the dataset, or a member of a parent Agency if a hierarchical agency structure is in place.
Maintaining Metadata Values on Series – Procedures
The Manage Metadata table is a spreadsheet-style web user interface that allows the value for each Dimension and Attribute to be set individually for each series.
Changing Metadata Values
Clicking on a cell displays a list of values to pick from.

Cells where values have been changed but not saved are highlighted.
- Save Mapping saves all of the highlighted changes, plus any series that have been added, and series deletions.
 Revert All Changes cancels all changes that have been made without saving.
Revert All Changes cancels all changes that have been made without saving.

There is no ‘undo’ function.
Changing Multiple Cells at Once
The same value can be set in multiple cells by using CTRL-RightClick to highlight multiple cells for a particular Dimension or Attribute.
The ![]() control in the column header allows a value to be set for all of the selected cells in one operation.
control in the column header allows a value to be set for all of the selected cells in one operation.
Code Label Display

Changes the way information is displayed in the table.
- ID Only – Just the short ID codes are displayed
- Name Only – Just names are displayed in the language of choice
- ID and Name – Both IDs and Names are displayed
Column Filters and Searching for Series
Excel-style column filters are provided on each Dimension and Attribute column.
You can use the Series Code column filter to search for specific series by Series Code or Series Name.
 clears all filters
clears all filters
Bulk Maintenance of Metadata Values using Excel Import / Export – Fusion Data Mapper
For bulk changes, a dataset’s metadata mappings can be exported to Excel, the spreadsheet modified offline to make the necessary changes, and imported.
Maintaining Metadata Values using Excel – Prerequisites
- One or more mapped datasets have been added (see Section 4.1).
- For each dataset, one or more series have been added (see Section 4.4).
Maintaining Metadata Values using Excel – Required Roles and Privileges
To maintain metadata values on a series, users must be a member of the Agency that owns the SDMX Structure Set and Dataflow Map that represents the dataset, or a member of a parent Agency if a hierarchical agency structure is in place.
Maintaining Metadata Values using Excel – Procedures
Using the Fusion Data Mapper:
Exporting Existing Mappings to Excel
Choose the dataset and select the Manage Metadata page from the left-hand menu.
Use the column filters to select the series to export – only the series shown in the table will be included in the spreadsheet.
Use the ![]() button to start the export and save the Excel file when prompted.
button to start the export and save the Excel file when prompted.
Modifying Exported Mappings
The Excel spreadsheet follows the layout shown in the Figure 4 example.
Series can be added by adding rows, and the metadata values set and modified.
Note that the Excel import will only remove series from a dataset when the “Full Replace” option is used. See below for more information on difference between the “Append” and “Full Replace” options. For most purposes, the interactive series removal function detailed in Section 4.6 is recommended unless the number of series to be removed is large.
The following rules should be observed when modifying exported Excel metadata sheets:
- Columns must not be added to or deleted from the spreadsheet. The Excel import function expects to find a column for each Dimension and Attribute in the dataset’s DSD.
- Every row must have the code of a “registered series” in the SERIES_CODE column. See Section 4.5 for information on how to register a series.
- Each series must appear only once.
- The Row A header must not be modified
- For coded Dimensions or Attributes, only valid codes must be used – valid codes are those in the relevant Codelist for the Dimension or Attribute
Blank metadata value cells are allowed and behave as follows when the spreadsheet is imported:
- For coded Dimensions and coded mandatory Attributes, the default value will be used.
- For un-coded mandatory Attributes, the metadata value with be set to an empty string or zero depending on whether the representation is string or numeric.
- For un-coded non-mandatory Attributes, no mapping will be created meaning that the Attribute will not appear in a data query result.
Importing Mappings from Excel
Choose the dataset and select the Manage Metadata page from the left-hand menu.
The ![]() button starts the import.
button starts the import.
In the Excel Import dialogue, choose Browse to search for the Excel file to import. Drag-and-drop can also be used by dragging a file from Windows Explorer onto the Browse box.
Two Import Modes are provided: Append and Full Replace.
“Append” Behaviour:
• New series that appear in the Excel spreadsheet but not in the existing dataset are added with the values specified for each dimension. Blank cells follow the rules set out above. • For existing series, the values are updated to those specified in the spreadsheet. Blank cells follow the rules set out above meaning that existing values will be reset to the default if the cell is blank. • Existing series that do not appear in the spreadsheet will not be altered.
“Full Replace” Behaviour:
- The mappings for the dataset will be replaced exactly with those in the spreadsheet.
Specifically:
- The values for existing series will be changed to those in the spreadsheet with blank cells following the rules set out above.
- Existing series that do not appear in the spreadsheet will be removed.
- New series that appear in the spreadsheet but not in the dataset will be added with the values specified for each dimension. Blank cells follow the rules set out above.
Take care when using Full Replace to avoid unintentionally removing series from the dataset – any series not explicitly specified in the spreadsheet will be removed.
Use the  button to import the Excel spreadsheet.
button to import the Excel spreadsheet.
If the import is successful, the dataset metadata display will show the revised mappings.
The Excel mapping import function is an “atomic transaction” meaning that the system guarantees either all of the mappings in the spreadsheet will be imported or none at all. If an import error occurs, no changes will be made to the dataset.
Any import errors are displayed in an error window – an example is shown in Figure 6.

Troubleshooting Excel Import
| Error | Solution |
|---|---|
| The supplied file is not recognised as a valid xlsx file. | The file must be an Excel 2007+ spreadsheet |
| The code specified ‘<code-in-error>’ does not exist in the codelist | The spreadsheet contains an invalid code in a coded dimension or attribute. An invalid code is one that cannot be found in the Codelist for the component in the dataset’s DSD.
Correct the code in the spreadsheet or add the code to the relevant Codelist |
| Excel file contains unknown components | The spreadsheet contains one or more columns with headers that do not match components in the dataset’s DSD.
Remove the invalid column(s) from the spreadsheet, or correct the name of the column in the header. If you need to change the dimensionality of the dataset, refer to Section 4.12 for guidance. |
| The series ‘<series-code-in-error>’ is not mappable as the value does not appear in the SERIES_CODE codelist | The spreadsheet contains one or more unregistered series. The series codes in the SERIES_CODE column must be in the CL_SERIES_CODE or equivalent codelist.
Correct the invalid series codes in the spreadsheet; or Remove the invalid series rows; or Register the series. See section 4.5 for more guidance on how to register series |
Default Code Values – Fusion Data Mapper
The first value in the relevant Codelist is the default for each coded Dimension or Attribute.
Setting a Default Code Value - Required Roles and Privileges
The user must be a member of the Agency that owns the SDMX Codelist, or a member of a parent Agency if a hierarchical agency structure is in place.
Setting the Default Code Value – Procedure
Use the Fusion Registry Administration Interface to change the ordering of codes in a Codelist:
- From the left-hand menu bar, choose Items and Codelists.
- Choose the relevant Codelist from those displayed. Using the Cogs menu, select ‘Edit the selected Codelist’.
- Move to Step 4 – Code Order & Hierarchy.
- Use the CSV Editor to change the ordering of the codes, placing the required default code in the top position.

Codelists - Adding and Removing Codes – Fusion Data Mapper
Codes are managed using the Fusion Registry Administration Interface.
Adding and Removing Codes – Prerequisites
- The Codelist exists.
Adding and Removing Codes - Required Roles and Privileges
The user must be a member of the Agency that owns the SDMX Codelist, or a member of a parent Agency if a hierarchical agency structure is in place.
Adding and Removing Codes – Procedure
Using the Fusion Registry Administration Interface
Adding Codes to a Codelist
- From the left-hand menu bar, choose Items and Codelists.
- Choose the relevant Codelist from those displayed. Using the Cogs menu, select ‘Edit the selected Codelist’.
- Either user Step 2 – Import Codes or Step 3 – Manual Editing to add the new codes to the Codelist.
- Modify the ordering and the default value if required using Step 4.
Code IDs must conform to the SDMX rules for structure IDs. In summary: the ID must use Latin characters and can contain letters, numbers and ‘_’ characters. It cannot contain dots (‘.’) or other special characters such as ‘@’ or ‘$’.
Refer to Section 4.11 for information on how to add and change multilingual names for each code.
Removing Codes from a Codelist
Note that codes can only be removed from a Codelist if they are not referenced in a mapped dataset or in data that has been loaded into, or registered with, Fusion Registry. Attempting to remove a code that is in use will result in an error, an example of which is given in Figure 8.

Fusion Registry enforces this restriction to protect its content referential integrity.
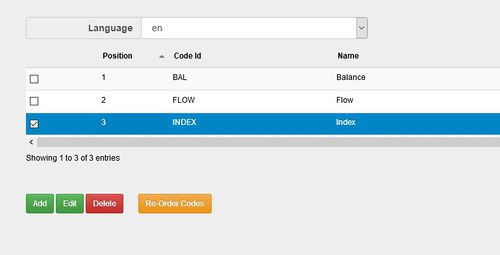
To remove codes that are not in use:
- From the left-hand menu bar, choose Items and Codelists.
- Choose the relevant Codelist from those displayed. Using the Cogs menu, select ‘Edit the selected Codelist’
- On Step 3 – Manual Editing, use the check boxes to select the codes and
 to complete the deletion. An example is shown in Figure 9.
to complete the deletion. An example is shown in Figure 9.
 === Codelists – Adding and Changing Multilingual Code Names with Impact Analysis ===
=== Codelists – Adding and Changing Multilingual Code Names with Impact Analysis ===

Code names can be changed, and alternative names in multiple languages set for the same code using the Fusion Registry Administration Interface (Codelist Maintenance) or the Fusion Data Mapper.
The Fusion Data Mapper additionally provides an impact analysis detailing the datasets and series that would be affected by the change, and is the procedure described here:
Adding and Changing Multilingual Code Names – Prerequisites
- The Codelist and code must exist.
Adding and Changing Multilingual Code Names – Required Roles and Privileges
The user must be a member of the Agency that owns the Codelist, or a member of a parent Agency if a hierarchy agency structure is in place.
Adding and Changing Multilingual Code Names – Procedure
Using the Fusion Data Mapper:
- Choose the dataset and select the Dataset Definition page from the left-hand menu.
- Choose the DSD Component from the list of Dimensions and Attributes shown. If it is coded, the Codelist will be shown in the right-hand panel.
- Select a code and choose
 to change its name.
to change its name. - The Impact Analysis shown details what datasets and series will be affected by the name change.
- Choosing a dataset displays a complete list of the series codes that will be affected.
- To change the name in a particular language, choose the language and enter the new name.
- Repeat Step 5 to change the name for the same code in other languages.

Changing the Dimensionality of a Dataset – Fusion Data Mapper
Use cases:
- Adding or removing dimensions
- Creating a copy of a dataset with completely different dimensionality
The dimensionality of a dataset is defined by its DSD which, once created, cannot be changed without deleting all of the metadata mappings that use it.
To change the dimensionality of a dataset, the recommended procedure is to create a new dataset with the required dimensionality and copy the series and mapping rules from the old dataset to the new.
Two methods are available:
- Excel Export / Import
- Clone Dataset
Excel Export / Import Method
Changing the Dimensionality of a Dataset – Prerequisites
- The dataset to change exists.
- The SERIES_CODE dimensions in the old and new DSDs must share the same Codelist, or the Codelists must contain the same series codes that you want to map.
Changing the Dimensionality of a Dataset - Required Roles and Privileges
The user must be a member of the Agency that owns the SDMX Structure Set, or a member of a parent Agency if a hierarchical agency structure is in place.
Changing the Dimensionality of a Dataset – Procedure
Create a new dataset using the DSD describing the revised dimensionality. To keep the same SDMX Dataflow, specify the same Dataset ID, but with a new version number, e.g. 1.1 or 2.0. Export the complete set of series mappings into Excel from the old dataset. Modify the Excel to add or remove dimension columns in the Excel to match the DSD of the new dataset. If adding dimension columns, blank cells will result in the default values being used. Import the Excel into the new dataset.
Clone Dataset Method
Changing the Dimensionality of a Dataset – Prerequisites
- The dataset to change exists.
- The SERIES_CODE dimensions in the old and new DSDs must share the same Codelist, or the Codelists must contain the same series codes that you want to map.
Changing the Dimensionality of a Dataset - Required Roles and Privileges
The user must be a member of the Agency that owns the SDMX Structure Set, or a member of a parent Agency if a hierarchical agency structure is in place.
Changing the Dimensionality of a Dataset – Procedure
- Follow the procedure for cloning datasets explained in Section 4.2.
Controlling User Privileges to Maintain and Browse Metadata Mappings
Maintenance Privileges – Fusion Data Mapper
To maintain (create or change) dataset mappings, the user must be a member of the Agency that owns the SDMX Structure Set, or a member of a parent Agency if a hierarchical agency structure is in place.
Structure Sets are containers that hold one or more mapped datasets.
Create separate Structure Sets owned by different Agencies or Sub-Agencies if you need to allow specific users to maintain certain datasets, but not others.
Example 1
In the following example, two Structure Sets are defined:
| Structure Set: | GENERAL_STATISTICS | Agency: STATS |
| Structure Set: | RESTRICTED_STATISTICS | Agency: RESEARCH |
A user who is a member of the STATS Agency group only will be able to create and change mapped datasets in the GENERAL_STATISTICS Structure Set, but not in the RESTRICTED_STATISTICS Set.
Users who are not members of either the STATS or RESEARCH Agency groups will be unable to maintain any of the mapped datasets.
Example 2 – Sub-Agencies
An alternative approach is to use Sub-Agencies to manage maintenance rights.
| Structure Set: | GENERAL_STATISTICS | Agency: MYAGENCY.GENERAL |
| Structure Set: | RESTRICTED_STATISTICS | Agency: MYAGENCY |
In this example, a user who is a member of the MYAGENCY ‘parent’ Agency group will be able to maintain mapped datasets in both the GENERAL_STATISTICS and RESTRICTED_STATISTICS Structure Sets. However, those only in the MYAGENCY.GENERAL Sub-Agency group, will only have maintenance rights for the GENERAL_STATISTICS Structure Set.
Creating Structure Sets
Structure Sets can be created and maintained using the Fusion Registry Administration Interface.
Browse Privileges – Fusion Data Mapper
Users who do not have maintenance privileges may still be able to browse the mapped datasets, depending on the Content Security rules in place.
If Content Security ‘Structure Rules’ have been defined for a structure, only the groups of users that have been explicitly granted access will be able to browse that structure or any structures that depend upon it.

The example in Figure 12 illustrates a Content Security rule restricting browsing of the Structure Set ‘Restricted Datasets’ to the group ‘Superusers’.
Content Security Metadata Management Use Cases – Fusion Data Mapper
A full explanation of how to administer Content Security rules is beyond the scope of this guide. However, details of some of the key use cases are given here.
Use Case – Restricting Who Can Browse Specific Datasets
Create rules to restrict access to specific Structure Sets.
- Create one or more separate Structure Sets to hold the datasets that need to be restricted.
- Create Content Security Structure rules to restrict access on each Structure Set to specific user groups.
- A Structure Set can be browsed by all users (including anonymous / unauthenticated users) if no Content Security rules are specified for it.
Use Case - Restricting Visibility of Certain Series in a Dataset
Series are only visible to users if all of the Codes used in the mapping are accessible.
Use Structure Rules to restrict access to specific Codes in Codelists used by the dataset.
Example 1
| SERIES_CODE | FREQ | DATA_SOURCE | SUBJECT |
|---|---|---|---|
| A_SERIES | A (Annual) | FM (Finance Ministry) | NA (National Accounts) |
| ANOTHER_SERIES | A (Annual) | CBS (Statistics Office) | ED (External Debit) |
| A_THIRD_SERIES | D (Daily) | CBS (Statistics Office) | ED (External Debit) |
Restricting the code ‘ED’ in the CL_SUBJECT Codelist which is used by the SUBJECT component to just the SUPERUSER group means that neither the ‘ANOTHER_SERIES’ or ‘A_THIRD_SERIES’ series will not be visible to other users.

Example 2
| SERIES_CODE | FREQ | DATA_SOURCE | SUBJECT |
|---|---|---|---|
| A_SERIES | A (Annual) | FM (Finance Ministry) | NA (National Accounts) |
| ANOTHER_SERIES | A (Annual) | CBS (Statistics Office) | ED (External Debit) |
| A_THIRD_SERIES | D (Daily) | CBS (Statistics Office) | ED (External Debit) |
Visibility of individual series can be controlled by restricting access to their Series Codes. In the above example, restricting access to the code ‘A_SERIES’ in the CL_SERIES_CODE Codelist to the SUPERUSER group will hide just that series from other users.
Content Security Caveats – Fusion Data Mapper
Take care when creating Content Security rules to avoid unintentionally denying users access to browse and maintain the metadata on datasets
The key thing to remember is that restricting access to a structure will cause all structures that reference it to also be restricted.
Restricting a Codelist, for instance, could result in users being denied access to an entire Structure Set if that Codelist is a descendent. (A ‘descendent’ of a structure is one that is referenced by other structures on which the first depends).
The example shown in Figure 14 illustrates now restricting the CL_FREQ Codelist also causes Categorisations, Concept Schemes, Content Constraints, Data Structures, Dataflows, Provision Agreement and Structure Sets that reference it to be restricted.
