Difference between revisions of "Add a Mapped Dataset – Fusion Data Mapper"
| (7 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
[[Category:Fusion Data Mapper]] | [[Category:Fusion Data Mapper]] | ||
| Line 45: | Line 39: | ||
# Choose a Source Dataset from those available. All Dataflows in the Fusion Registry with a single dimension are shown in this list. However, it is important that the single dimension of the chosen source dataset must be the Series Code. If multiple Source Datasets are shown in the list, care should be taken to choose the correct one otherwise it will be impossible to create the metadata mappings. | # Choose a Source Dataset from those available. All Dataflows in the Fusion Registry with a single dimension are shown in this list. However, it is important that the single dimension of the chosen source dataset must be the Series Code. If multiple Source Datasets are shown in the list, care should be taken to choose the correct one otherwise it will be impossible to create the metadata mappings. | ||
# Choose the Dataset Definition for the new dataset. A list of available Data Structure Definitions (DSDs) are shown to choose from. | # Choose the Dataset Definition for the new dataset. A list of available Data Structure Definitions (DSDs) are shown to choose from. | ||
| − | #:::The DSD chosen for the new dataset must follow these rules: | + | #:::[[File:Triangle.jpg|frameless|30px]] The DSD chosen for the new dataset must follow these rules: |
#:::* the DSD must include a SERIES_CODE dimension | #:::* the DSD must include a SERIES_CODE dimension | ||
#:::* the SERIES_CODE dimension must be coded (conventionally, the Codelist is named CL_SERIES_CODE) | #:::* the SERIES_CODE dimension must be coded (conventionally, the Codelist is named CL_SERIES_CODE) | ||
| − | #:::* the codes of series in the Time Series Database to be included in the dataset must be ‘registered’ by adding them to the SERIES_CODE Codelist (refer to [[Registering a Series| | + | #:::* the codes of series in the Time Series Database to be included in the dataset must be ‘registered’ by adding them to the SERIES_CODE Codelist (refer to [[Registering a Series – Fusion Data Mapper|Registering a Series]]) |
#:::If an invalid DSD is chosen, the dataset will be created but it will be impossible to add series to it. | #:::If an invalid DSD is chosen, the dataset will be created but it will be impossible to add series to it. | ||
| − | # Set the name for the new Dataset in the chosen language. This the descriptive name of mapped dataset’s Dataflow, for instance ‘Employment’, ‘National Accounts’ or ‘Financial Activity’. After the Dataset has been created, changes to the name, including adding alternative names in different languages, can be made using the Fusion Registry Administration Interface – Dataflow maintenance. In the example shown | + | # Set the name for the new Dataset in the chosen language. This the descriptive name of mapped dataset’s Dataflow, for instance ‘Employment’, ‘National Accounts’ or ‘Financial Activity’. After the Dataset has been created, changes to the name, including adding alternative names in different languages, can be made using the Fusion Registry Administration Interface – Dataflow maintenance. In the example shown the name has been set in Hebrew. |
# Set the SDMX ID for the new dataset. The ID is the unique reference for the dataset’s SDMX Dataflow. You must follow these rules when choosing the ID: | # Set the SDMX ID for the new dataset. The ID is the unique reference for the dataset’s SDMX Dataflow. You must follow these rules when choosing the ID: | ||
#:::*The ID must be unique | #:::*The ID must be unique | ||
| Line 60: | Line 54: | ||
#::::NATIONAL_ACCOUNTS | #::::NATIONAL_ACCOUNTS | ||
#:::*By convention, IDs are in upper case. For example, use ‘NATIONAL_ACCOUNTS’ rather than ‘National_Accounts’ | #:::*By convention, IDs are in upper case. For example, use ‘NATIONAL_ACCOUNTS’ rather than ‘National_Accounts’ | ||
| − | #::[[File:SS3.jpg|frameless|500px|'' | + | #::[[File:SS3.jpg|frameless|500px|''Add Dataset Example'']] |
#Set the Version for the dataset. This will be used to set the version of the dataset’s SDMX Dataflow. Version numbers are of the form <major_number>.<minor_number>. The following are valid: | #Set the Version for the dataset. This will be used to set the version of the dataset’s SDMX Dataflow. Version numbers are of the form <major_number>.<minor_number>. The following are valid: | ||
#:1.0 | #:1.0 | ||
| Line 67: | Line 61: | ||
#:By convention, the first version is 1.0. | #:By convention, the first version is 1.0. | ||
#: | #: | ||
| − | #:Create new versions of a dataset when you need to change the dimensionality – refer to [[ | + | #:Create new versions of a dataset when you need to change the dimensionality – refer to [[Changing the Dimensionality of a Dataset – Fusion Data Mapper|Changing the Dimensionality of a Dataset]]. |
#Choosing ‘Add’ will create the new dataset which should then appear in the left-hand bar | #Choosing ‘Add’ will create the new dataset which should then appear in the left-hand bar | ||
#::[[File:Pic2.jpg|frameless|500px]] | #::[[File:Pic2.jpg|frameless|500px]] | ||
Latest revision as of 06:22, 11 September 2023
A mapped dataset is an SDMX Dataflow and an associated SDMX Dataflow Map that describes:
- (a) The dataset’s dimensionality using an SDMX Data Structure Definition (DSD)
- (b) The list of series in the dataset
- (c) The metadata values for each series
Use cases:
- Creating a new dataset
- Creating an alternative version of an existing dataset perhaps with a different compliment of series and / or dimensionality
- Creating an alternative version of a dataset with simplified dimensionality for public dissemination
The Fusion Data Mapper provides a convenient way to interactively manage the process. However, it is important to note that creating, modifying and examining the underlying SDMX artefacts can also be done using the Fusion Registry Administration Interface or the REST API which may be useful for debugging purposes. Discussion of these topics is outside of the scope of this document.
Add a Mapped Dataset - Prerequisites
- The DSD that you plan to use for the dataset must already exist. DSDs and their associated structures can be created and managed using the Fusion Registry Administration User Interface.
- The Source Dataset that contains the unmapped time series observations. The Source Dataset is an SDMX Dataflow created by a System Administrator that provides access to the Time Series Database observation data.
Add a Mapped Dataset - Required Roles and Privileges
To add a mapped dataset, the user must be a member of the Agency that owns the SDMX Structure Set, or a member of a parent Agency if a hierarchical agency structure is in place.
Once created, the SDMX Dataflow Map which represents the dataset will be owned by the same Agency as the SDMX Structure Set to which it belongs. Any subsequent changes to the dataset can only be performed by users who are a member of that Agency. Changes include:
- Removing the dataset
- Adding and removing series
- Maintaining the metadata values on series
Add a Mapped Dataset - Procedure
Using the Fusion Data Mapper:
- Choose the Add Dataset function from the left-hand menu bar.
- Choose a Source Dataset from those available. All Dataflows in the Fusion Registry with a single dimension are shown in this list. However, it is important that the single dimension of the chosen source dataset must be the Series Code. If multiple Source Datasets are shown in the list, care should be taken to choose the correct one otherwise it will be impossible to create the metadata mappings.
- Choose the Dataset Definition for the new dataset. A list of available Data Structure Definitions (DSDs) are shown to choose from.
 The DSD chosen for the new dataset must follow these rules:
The DSD chosen for the new dataset must follow these rules:
- the DSD must include a SERIES_CODE dimension
- the SERIES_CODE dimension must be coded (conventionally, the Codelist is named CL_SERIES_CODE)
- the codes of series in the Time Series Database to be included in the dataset must be ‘registered’ by adding them to the SERIES_CODE Codelist (refer to Registering a Series)
- If an invalid DSD is chosen, the dataset will be created but it will be impossible to add series to it.
- Set the name for the new Dataset in the chosen language. This the descriptive name of mapped dataset’s Dataflow, for instance ‘Employment’, ‘National Accounts’ or ‘Financial Activity’. After the Dataset has been created, changes to the name, including adding alternative names in different languages, can be made using the Fusion Registry Administration Interface – Dataflow maintenance. In the example shown the name has been set in Hebrew.
- Set the SDMX ID for the new dataset. The ID is the unique reference for the dataset’s SDMX Dataflow. You must follow these rules when choosing the ID:
- The ID must be unique
- The ID must use Latin characters and can contain letters, numbers and ‘_’ characters.
- It cannot contain dots (‘.’) or other special characters such as ‘@’ or ‘$’.
- The following are valid:
- EMPLOYMENT
- FINANCIAL_ACTIVITY2
- NATIONAL_ACCOUNTS
- By convention, IDs are in upper case. For example, use ‘NATIONAL_ACCOUNTS’ rather than ‘National_Accounts’
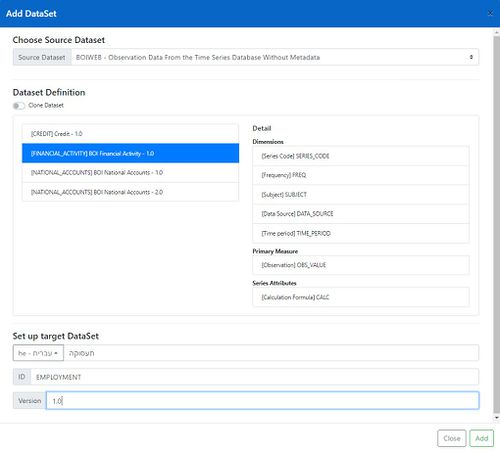
- Set the Version for the dataset. This will be used to set the version of the dataset’s SDMX Dataflow. Version numbers are of the form <major_number>.<minor_number>. The following are valid:
- 1.0
- 1.1
- 2.1
- By convention, the first version is 1.0.
- Create new versions of a dataset when you need to change the dimensionality – refer to Changing the Dimensionality of a Dataset.
- Choosing ‘Add’ will create the new dataset which should then appear in the left-hand bar


